A beginner-friendly tutorial on DCGAN with PyTorch to generate Fake celebrity images with CelebA dataset.
GANs
Published
November 16, 2020
Keywords
GANs, PyTorch, deep learning, python
This article can be opened as Jupyter Notebook to train DCGAN on CelebA dataset to generate fake celebrity images.
What is DCGAN?
DCGAN (Deep Convolutional Generative Adversarial Network) is created by Alec Radford, Luke Metz and Soumith Chintala in 2016 to train Deep Generative Adversarial Networks. In the DCGAN paper, the authors trained the network to produce fake faces of celebrities and fake bedroom images.
The architecture consists of two networks - Generator and Discriminator. Generator is the heart of GANs. It produces real looking fake images from random noise.
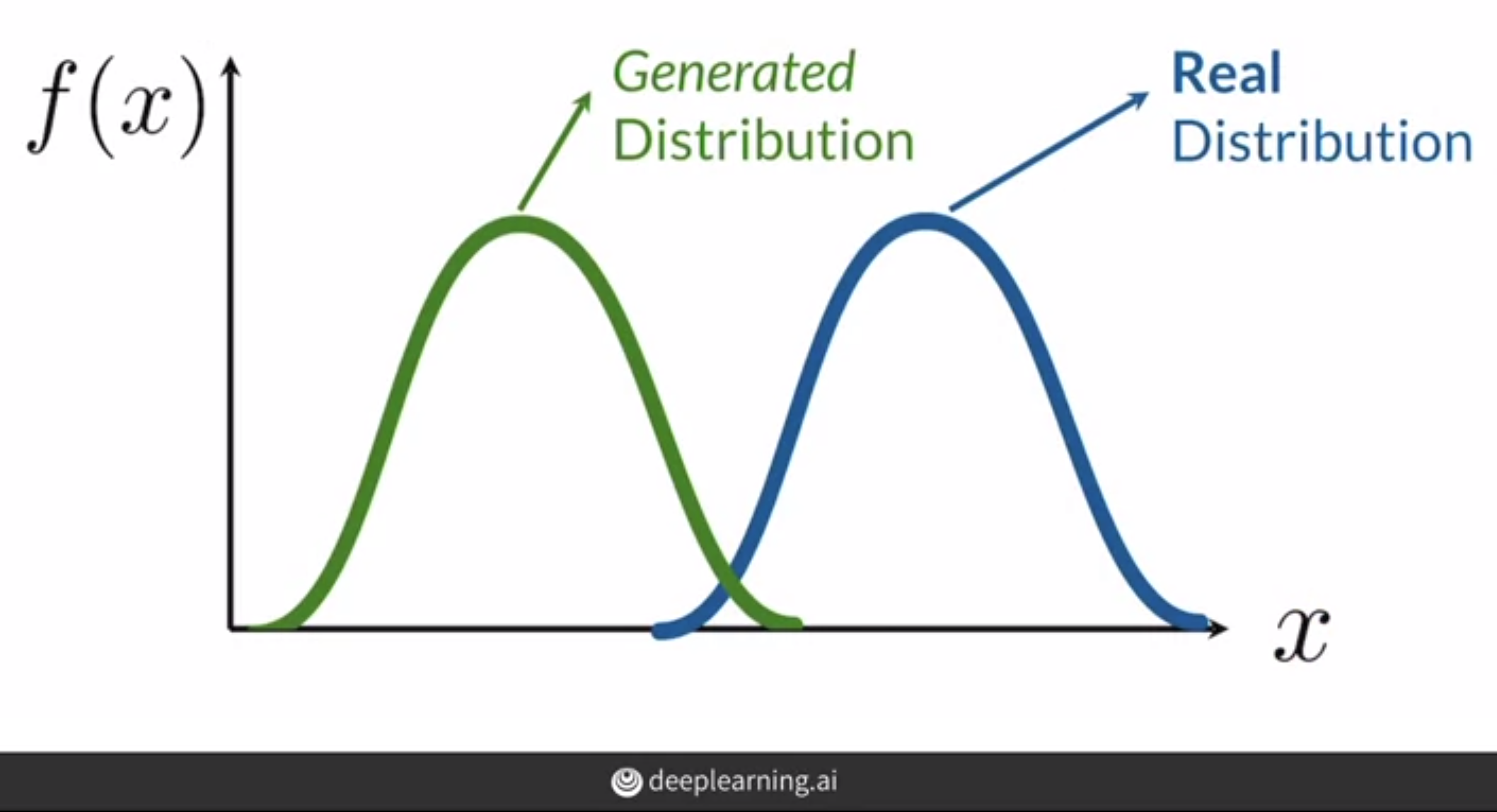
Discriminator wants the real and fake image distributions to be as far as possible while the Generator wants to reduce the distance between the real and fake image distribution. In simple words, the Generator tries to fool the Discriminator by producing real looking images while the Discriminator tries to catch the fake images from the real ones.
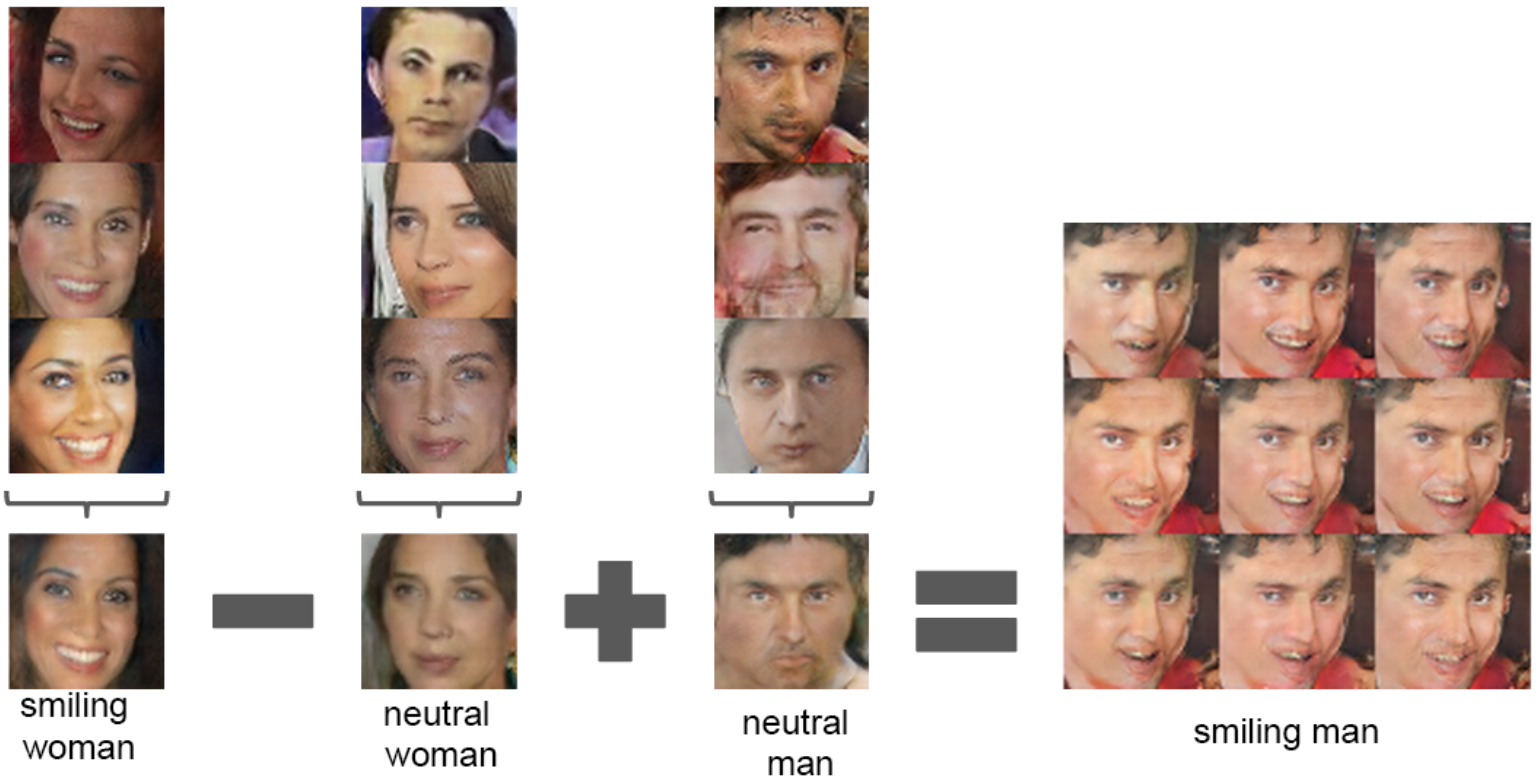
Vector arithmetic for visual concepts. Source: Paper
Training details from the paper
Preprocessing: Images are scaled to be in range of tanh activation, [-1, 1]. Training was done with a mini-batch size of 128 and Adam optimizer with a learning rate of 0.0002. All the weights initialised with Normal distribution \(\mu(0, 0.02)\).
Authors guidelines: - All the pooling layers are replaced with strided convolutions in the discriminator and fractional strided convolution in the discriminator. - No fully-connected or pooling layers are used. - Batchnorm used in both Generator and Discriminator - ReLu activation is used for generator for all the layers except the last layer which uses tanh - Discriminator uses LeakyReLu for all the layers
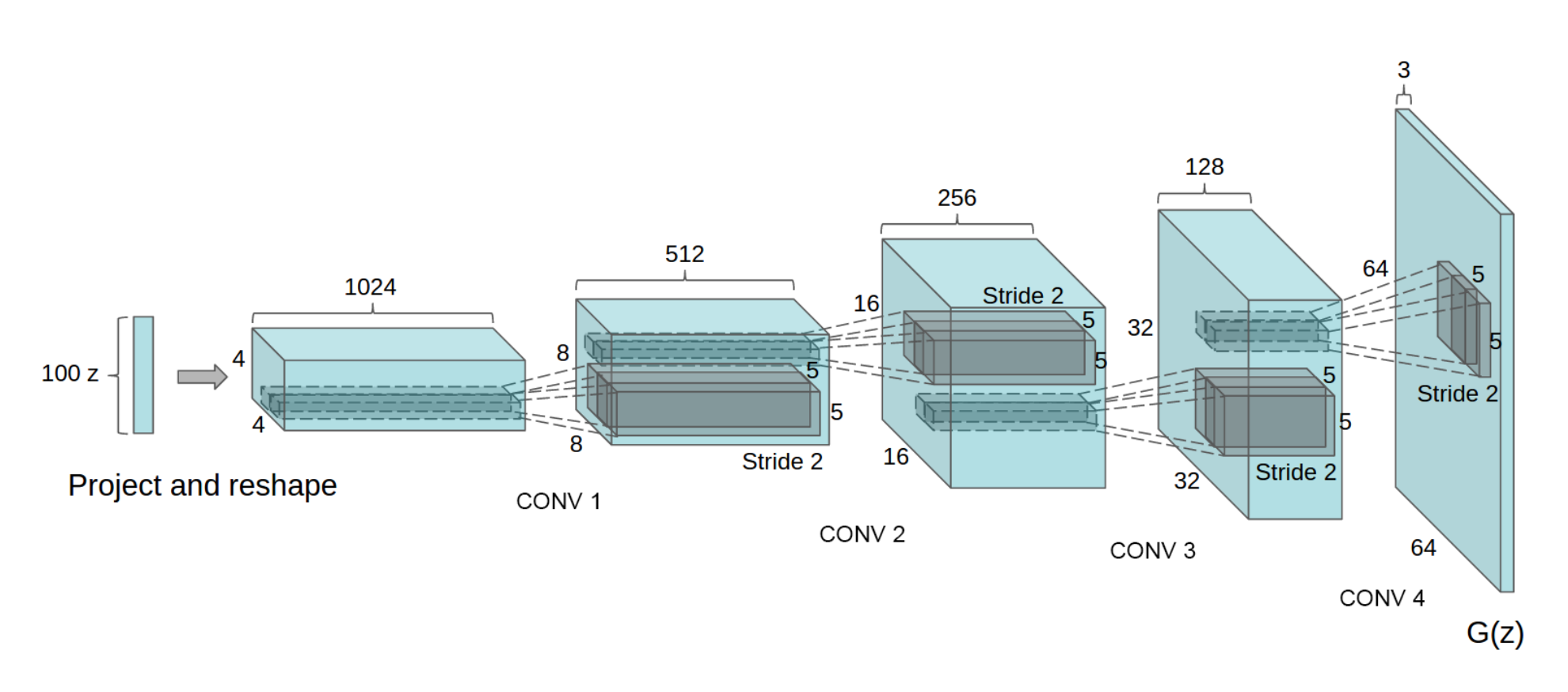
In this post I will train a GAN to generate celebrity faces. ## Generator A Generator consists Transposed Convolution, Batch Normalisation and activation function layer. - First the random noise of size 100 will be reshaped to 100x1x1 (channel first in PyTorch). - It is passed through a Transposed CNN layer which upsamples the input Tensor. - Batch Normalisation is applied. - If the layer is not the last layer then ReLu activation is applied else Tanh.
First channel size is 1024 which is then decreased block by block to 3 for RGB image. Finally we will get a 3x64x64 Tensor which will be our image.
def show_tensor_images(image_tensor, num_images=25, size=(3, 64, 64)):""" Function for visualizing images: Given a tensor of images, number of images, and size per image, plots and prints the images in an uniform grid. """ image_tensor = (image_tensor +1) /2 image_unflat = image_tensor.detach().cpu() image_grid = make_grid(image_unflat[:num_images], nrow=5) plt.imshow(image_grid.permute(1, 2, 0).squeeze()) plt.show()
The architecture of a Discriminator is same as that of a normal image classification model. It contains Convolution layers, Activation layer and BatchNormalisation. In the DCGAN paper, strides are used instead of pooling to reduce the size of a kernel. Also there is no Fully Connected layer in the network. Leaky ReLU with leak slope 0.2 is used.
The Discriminator wants to predict the fake images as fake and real images as real. On the other hand the Generator wants to fool Discriminator into predicting the fake images produced by the Generator as real.
# You can tranform the image values to be between -1 and 1 (the range of the tanh activation)transform = transforms.Compose( [ transforms.Resize(64), transforms.CenterCrop(64), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])dataloader = DataLoader( datasets.CelebA(".", download=True, transform=transform), batch_size=batch_size, shuffle=True,)
Training Loop
Binary Crossentropy loss, \(J(\theta) = -1/m \sum[y^i logh[X^i, \theta] + (1-y^i)log(1-h[X^i, \theta)]\), for training DCGAN.
Discriminator Loss
As the discriminator wants to increase the distance between Generated and Real distribution, we will train it to give high loss when the generated images is classified as real or when real images are classified as fake.
Generator Loss
The BCE loss for Generator will be high when it fails to fool the Discriminator. It will give high loss when the generated image is classified as fake by the discriminator. Note that the Generator never know about real images.