Projects
FastServe
Machine Learning Serving focused on GenAI with simplicity as the top priority. Dynamic batching powered by pure Python implementation.
To serve Image-to-Text API using SSD-1B:
from fastserve.models import FastServeSSD
serve = FastServeSSD(device="cuda", batch_size=4, timeout=1)
serve.run_server()Muse (Stable Diffusion Deployment)
Open source, stable-diffusion production server to show how to deploy diffusion models in a real production environment with: load-balancing, gpu-inference, performance-testing, micro-services orchestration and more. All handled easily with the Lightning Apps framework.

Discord LLM Bot
Retrieval Augmented Genration (RAG) powered Discord Bot that works seamlessly on CPU. Powered by LanceDB and Llama.cpp. This Discord bot is designed to helps answer questions based on a knowledge base (vector db).
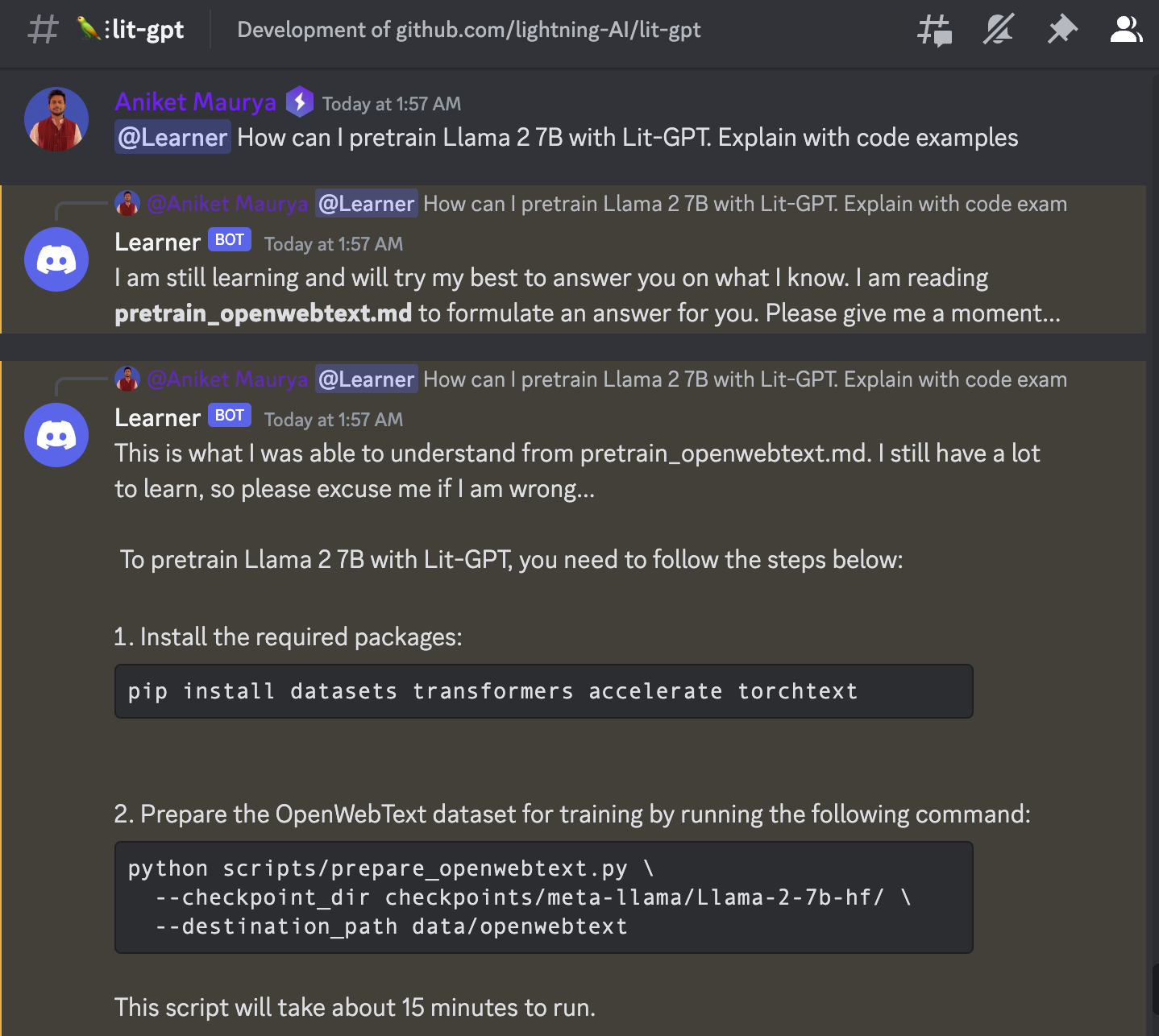
LLM Inference
Large Language Model (LLM) Inference API and Chatbot 🦙

Build and run LLM Chatbot under 7 GB GPU memory in 5 lines of code.
from llm_chain import LitGPTConversationChain, LitGPTLLM
from llm_inference import prepare_weights
path = str(prepare_weights("meta-llama/Llama-2-7b-chat-hf"))
llm = LitGPTLLM(checkpoint_dir=path, quantize="bnb.nf4") # 7GB GPU memory
bot = LitGPTConversationChain.from_llm(llm=llm, prompt=llama2_prompt_template)
print(bot.send("hi, what is the capital of France?"))Gradsflow
An open-source AutoML Library based on PyTorch

Chitra
A multi-functional library for full-stack Deep Learning. Simplifies Model Building, API development, and Model Deployment.
